Apache Ignite 分布式事务原理
Apache Ignite 分布式事务原理
Apache Ignite 是一个高性能、集成化和分布式的内存计算平台,支持在大数据量场景下进行 SQL 查询、计算和事务处理。在本文中,我们将深入探讨 Apache Ignite 中分布式事务的实现原理。
使用示例
首先,让我们通过一个简单的示例来了解如何在 Ignite 中使用事务:
1 | |
两阶段提交协议
Ignite 中的事务基于经典的两阶段提交(2PC)协议实现,确保跨多个节点和缓存的原子性。
两阶段提交协议包括以下两个阶段:
- 准备阶段(Prepare Phase):事务协调器向所有参与者发送准备请求,参与者执行事务但不提交,然后向协调器报告是否准备好提交事务。
- 提交阶段(Commit Phase):如果所有参与者都准备好,协调器发送提交请求,所有参与者正式提交事务;如果有任何一个参与者未准备好,协调器发送回滚请求。
这种机制确保了分布式事务的一致性,即使在节点故障的情况下也能维持数据完整性。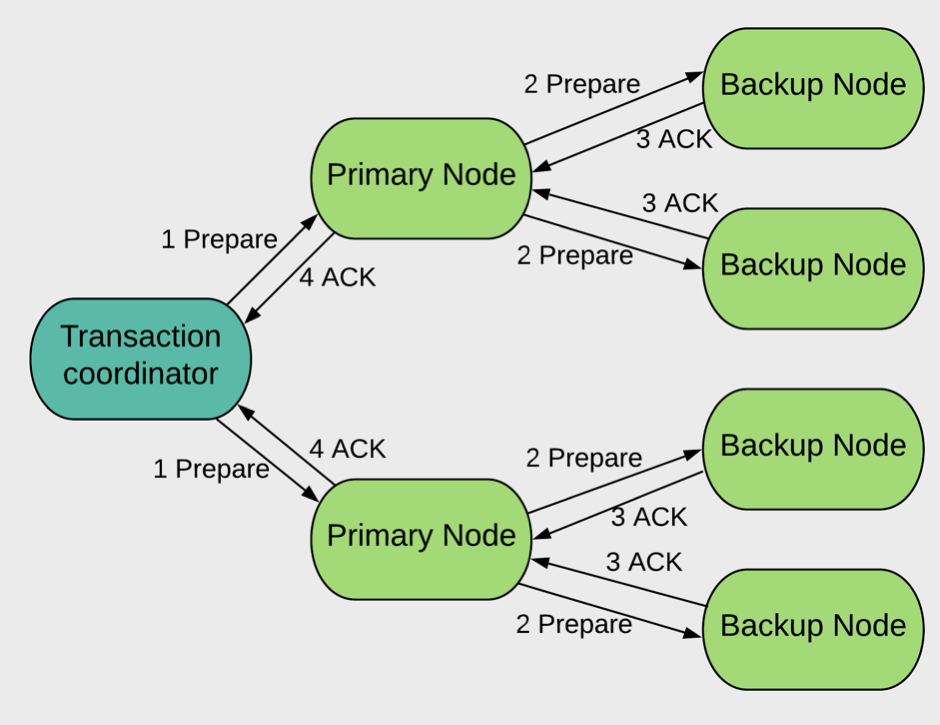
prepare 阶段
客户端发送一个准备消息(1 Prepare)给事务涉及的所有主节点
主节点获得所有的锁(取决于事务为悲观还是乐观),然后转发准备消息(2 Prepare)给所有的备节点
每个节点会给客户端一个确认(3 ACK, 4 ACK),即所有的锁已经成功获得然后事务准备提交。
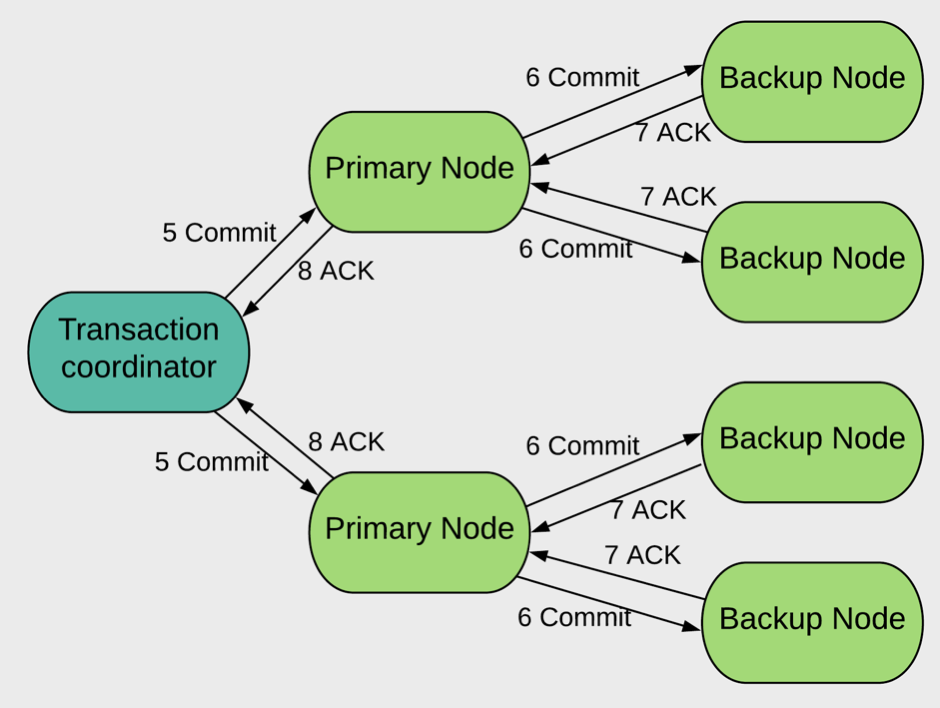
commit 阶段
客户端发送提交消息(5 Commit)给事务涉及的所有主节点;
主节点提交事务并且转发提交消息(6 Commit)给所有的备节点,然后备节点提交事务;
每个节点返回事务提交成功的确认消息给客户端(7 ACK, 8 ACK)。
并发模型和隔离级别
事务确保系统从一个一致状态切换到另一个一致状态。在分布式环境中,Ignite 提供了多种并发控制机制和隔离级别。
锁机制
事务依赖于锁机制,锁可以在第一次操作数据时(悲观锁)获得,也可以在事务结束提交之前(乐观锁)获得。
悲观并发模型
悲观并发模型假设会发生冲突,因此在第一次操作数据时就锁定即将要读、写或者修改的所有数据。这种模型适用于高争用场景,可以避免事务冲突导致的回滚。
Ignite 支持以下悲观并发模型的隔离级别:
读已提交(READ_COMMITTED)
在该级别下:
- 锁是在写操作对数据进行任何改变之前获得的,比如 put() 或者 putAll()
- 对于读操作不会获得锁,比如 get() 或者 getAll()
可重复读(REPEATABLE_READ)
在该隔离级别下,读写操作都需要获得锁,确保在事务执行期间,同一数据的多次读取结果一致。
序列化(SERIALIZABLE)
最高的隔离级别,同样要求读写操作都获得锁,确保事务串行执行,完全避免并发问题。
乐观并发模型
与悲观并发模型相反,乐观并发模型假设冲突很少发生,因此延迟了锁的获取,直到事务提交时才检查冲突。这种模型更适合于资源争用较少的应用场景。
乐观并发模型支持与悲观模型相同的隔离级别:
- 读已提交
- 可重复读
- 序列化
故障和恢复
在分布式环境中,节点故障是不可避免的。Ignite 设计了完善的故障恢复机制来处理各种故障场景。
分布式集群由事务协调器、主节点和备份节点组成。按照严重程度递增的顺序,可能的故障类型包括:
备份节点故障
在二阶段提交协议中,有准备和提交阶段。不管是哪个阶段,如果备份节点故障,对 Ignite 都不会产生影响,因为事务会继续在集群中剩余的主备节点上执行。
在所有的活动事务(包括这一个)结束之后,Ignite 会因为节点故障而更新网络拓扑版本,然后选择一个或者多个节点来持有之前故障节点持有的数据。Ignite 会在后台启动再平衡过程来满足所需的数据复制级别。
主节点故障
主节点故障的影响取决于故障发生的时间:
如果故障发生在准备阶段
事务协调器会抛出一个异常,应用需要决定如何处理这个异常以及下一步怎么做,比如是重启事务或其他的异常处理。
如果故障发生在提交阶段
事务协调器会等待来自某个备份节点的特定消息(4 ACK)。当备份节点检测到故障时,它会通知事务协调器事务已经成功提交。这时,因为有备份所以数据没有丢失,并且也不影响应用对数据的访问和使用。
事务协调器完成事务之后,因为主节点故障所以 Ignite 会进行集群的再平衡,它会选举一个新的主节点替代故障的主节点。
事务协调器故障
此时主节点和备份节点只能感知到本地的事务状态,无法知道全局的事务状态。只有部分节点会收到提交消息而其他的收不到。
这个故障场景的解决方案是,节点间互相交换它们的本地事务状态,这样他们就知道了全局事务状态。这时,Ignite 会发起一个恢复协议来处理这种情况,流程比较复杂。
Ignite 持久化层中的事务处理
Ignite 提供了原生持久化功能,可以将数据存储在磁盘上,同时保持内存级的性能。
预写日志(WAL)
开启 Ignite 持久化之后,对于节点上的每个分区,Ignite 会维护一个专用的分区文件。当内存中的数据更新之后,更新不是直接写入对应的分区文件的,而是附加到预写日志(WAL)的末尾。
使用 WAL 与直接更新相比,会有一个显著地性能提升,此外,WAL 在集群或者节点故障时,还提供了一个恢复机制。
WAL 被拆分为若干个文件,叫做段。这些段是按照顺序填充的。默认会创建 10 个段,但是这个数值是可配置的。这些段文件的使用方式是,当第一个段满了之后,它会被复制到 WAL 归档文件,该文件会保持一段可配置的时间,在数据从第一个段复制到归档文件的过程中,第二个段就会处于激活状态,对于每个段文件,这个过程会循环执行。
每个更新首先都会被添加到 WAL,每个更新都会通过缓存 ID 和条目键唯一标识,因此,当故障或者重启时,集群总是能恢复到最近的成功提交的事务或者原子更新。
总结
Apache Ignite 的分布式事务实现基于成熟的两阶段提交协议,并提供了丰富的并发控制机制和故障恢复能力。通过悲观和乐观并发模型、多种隔离级别以及完善的持久化支持,Ignite 能够在保证数据一致性的同时,提供高性能的分布式事务处理能力。
无论是处理简单的键值操作还是复杂的跨多个缓存的事务,Ignite 都能提供可靠的支持,并在节点故障时保证数据的完整性和可用性。
 wechat
wechat